





Delve into the vast possibilities offered by the official OpenAI npm package. Discover its capabilities in generating texts, providing code completions, filtering content, and even generating images. Expand your imagination and explore the limitless potential of this cutting-edge technology.
Link to the official OpenAI npm package
The OpenAI NodeJS library provides convenient access to the OpenAI API from NodeJS applications. Most of the code in this library is generated from our OpenAPI > specification.
Important note: this library is meant for server-side usage only, as using it in client-side browser code will expose your secret API key. See here for more details.
Generate an API key from OpenAI
Sign in / login to then OpenAI website: https://openai.com/api/
Go to View API KEYS, by clicking on the top right corner on the profile picture to show the drop-down menu.
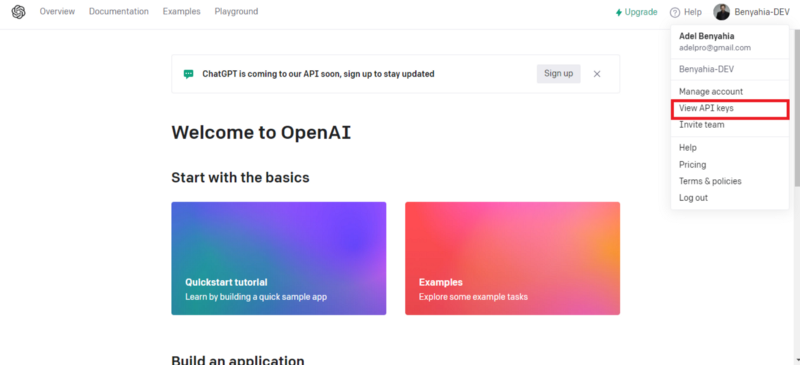
3. Click on the Create new secret key button to generate a new API key.
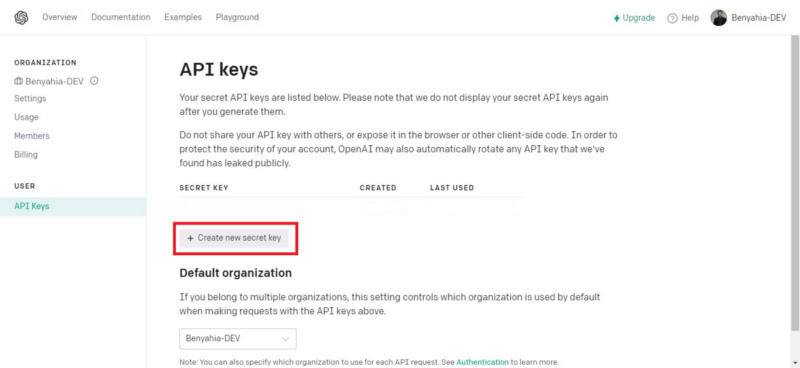
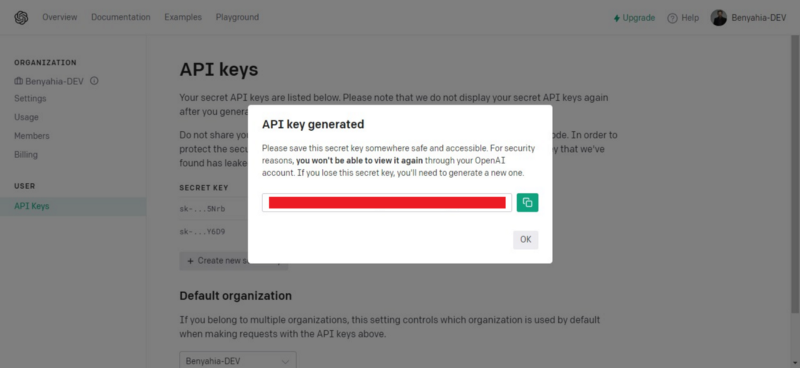
4. Copy the generated API key then click on the “OK” button to close the modal (don’t forget to copy, because the Key will be hidden for ever after).
Setup
Create a file named .env.
Add the generated API KEY to the .env file in the ./backend folder
APIKEY="xxxx...."
3. Install the dependencies
npm install
You have 3 dependencies
Express : Fast, unopinionated, minimalist web framework for Node.js.
dotenv : Dotenv is a zero-dependency module that loads environment variables from a .env file into process.env. Storing configuration in the environment separate from code is based on The Twelve-Factor App methodology.
openai : The OpenAI NodeJS library provides convenient access to the OpenAI API from Node.js applications. Most of the code in this library is generated from our OpenAPI specification.
4. Run server
npm start
Or in the development mode
npm run dev
N.B: We are using the new — watch flag in NodeJS 18 to continuously watch any changes in our files in development mode.
Usage
To access the API endpoints you have two choices:
To generate a text, send a post request to this endpoint:
With a body in JSON format that contain two options:
model : Contain the model to use, you have 3 model
1- GPT-3: A set of models that can understand and generate natural language
“text-davinci-003” Most capable GPT-3 model. Can do any task the other models can do, often with higher quality, longer output and better instruction-following. Also supports inserting completions within text.
“text-curie-001”: Very capable, but faster and lower cost than Davinci.
“text-babbage-001”: Capable of straightforward tasks, very fast, and lower cost.
“text-ada-001”: Capable of very simple tasks, usually the fastest model in the GPT-3 series, and lowest cost.
2- Codex Limited beta: A set of models that can understand and generate code, including translating natural language to code
“code-davinci-002” : Most capable Codex model. Particularly good at translating natural language to code. In addition to completing code, it also supports inserting completions within code.
“code-cushman-001” : Almost as capable as Davinci Codex, but slightly faster. This speed advantage may make it preferable for real-time applications.
3- Content filter A fine-tuned model that can detect whether text may be sensitive or unsafe
- “content-filter-alpha”
prompt : contain the text to pass to openAI
Let’s Code
To have a clean code, we will route / controllers structure
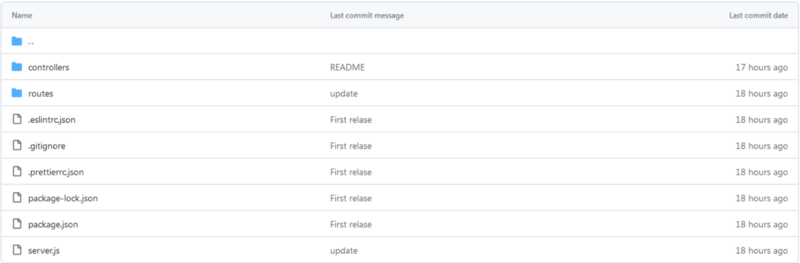
/Controllers: contain the callback functions that will be executed for each Route, in our case: openAIController.js
/routes: contain the different routes for our API, in our case: openAIRoutes.js
.eslintec.json: eslint configuration file
.gitignore: contain the list of files that we don’t wont to send to our git repository, in our case: node_modules, logs, .env
.prettierrc.json: prettier configuration file
package-lock.json and package.json: contain the configuration of our application: name, version, description, script, dependencies…
server.js: our main app file
First we will start by our “server.js” files
require('dotenv').config();
const express = require('express');
const app = express();
const port = process.env.PORT || 3500;
app.use(express.json());
app.use('/openai', require('./routes/openAIRoute'));
app.listen(port, () => {
console.log(`Server listening on port ${port}`);
});
It’s a simple NodeJS and ExpressJS server that
listen by default on port 3500
have one route: “/openai” that point to the callback function openAIRoute, all calls for this route will execute this function
Second our “/routes/openAIRoutes.js” file
const express = require('express');
const router = express.Router();
const openAIController = require('../controllers/openAIController');
router.route('/text').post(openAIController.openAIText);
router.route('/image').post(openAIController.openAIImage);
module.exports = router;
In our “/openai” route, we have two sub-routes:
“/text” for text based request, and will execute “openAIController.openAIText” callback function
“/image” for image based request, and will execute “openAIController.openAIImage” callback function
Our final API endpoints will look like this
http://localhost:3500/openai/text
or
http://localhost:3500/openai/image
Third our “/controllers/openAIController.js” file
const { Configuration, OpenAIApi } = require('openai');
const configuration = new Configuration({
apiKey: process.env.APIKEY,
});
const openai = new OpenAIApi(configuration);
// @desc openAI TEXT
// @Route POST /text
// @Access Public
const openAIText = async (req, res) => {
const { prompt, model } = req.body;
try {
const result = await openai.createCompletion({
model,
prompt,
temperature: 0,
max_tokens: 100,
});
return res.json({ result: result.data.choices[0].text });
} catch (error) {
if (error.response) {
console.log(error.response.status);
console.log(error.response.data);
return res
.status(error.response.status)
.json({ error: error.response.data });
} else {
console.log(error.message);
return res.status(500).json({ error: error.message });
}
}
};
// @desc openAI IMAGE
// @Route POST /image
// @Access Public
const openAIImage = async (req, res) => {
const { prompt } = req.body;
try {
const result = await openai.createImage({
prompt,
n: 1,
size: '512x512',
});
return res.json({ result: result.data.data[0].url });
} catch (error) {
if (error.response) {
console.log(error.response.status);
console.log(error.response.data);
return res
.status(error.response.status)
.json({ error: error.response.data });
} else {
console.log(error.message);
return res.status(500).json({ error: error.message });
}
}
};
module.exports = { openAIText, openAIImage };
As you can see we have exported two functions
openAIText: for the text based endpoint
openAIImage: for the image based endpoint
And each function have different configuration
openAIText function
// @desc openAI TEXT
// @Route POST /text
// @Access Public
const openAIText = async (req, res) => {
const { prompt, model } = req.body;
try {
const result = await openai.createCompletion({
model,
prompt,
temperature: 0,
max_tokens: 100,
});
return res.json({ result: result.data.choices[0].text });
} catch (error) {
if (error.response) {
console.log(error.response.status);
console.log(error.response.data);
return res
.status(error.response.status)
.json({ error: error.response.data });
} else {
console.log(error.message);
return res.status(500).json({ error: error.message });
}
}
};
Receive two parameters in the req.body:
prompt : that contain the text that we will pass to our openAI
model: contain the model that openAI will use to generate the result
For more details go to the Usage section of this article
openAIImage
// @desc openAI IMAGE
// @Route POST /image
// @Access Public
const openAIImage = async (req, res) => {
const { prompt } = req.body;
try {
const result = await openai.createImage({
prompt,
n: 1,
size: '512x512',
});
return res.json({ result: result.data.data[0].url });
} catch (error) {
if (error.response) {
console.log(error.response.status);
console.log(error.response.data);
return res
.status(error.response.status)
.json({ error: error.response.data });
} else {
console.log(error.message);
return res.status(500).json({ error: error.message });
}
}
};
Receive one parameter in the req.body:
- prompt : that contain the text that we will pass to our openAI
For more details go to the Usage section of this article
Examples
- Text generation :
URL :
http://locahlost:3500/openai/textmethod : post
body : {model:”text-davinci-003", prompt:”write me a 90 word about NodeJS”}
. Code completion :
URL:
http://localhost:3500/openai/textmethod : post
body : {model:”code-davinci-002", prompt:”const a = 1; const b = 10; console.log”}
- Image Generation :
method : post
body : {prompt:”Algerian desert”}
More advanced options
For Text
In openAIController file, got to the function : openAIText
const result = await openai.createCompletion({
model,
prompt,
temperature: 0,
max_tokens: 100,
});
max_tokens
(integer, Optional, Defaults to 16)
The maximum number of tokens to generate in the completion. The token count of your prompt plus max_tokens cannot exceed the model’s context length. Most models have a context length of 2048 tokens (except for the newest models, which support 4096).
temperature
(number, Optional, Defaults to 1)
What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
n
(integer, Optional, Defaults to 1)
How many completion to generate for each prompt.
For image
n (integer, Optional, Defaults to 1)
How many images to generate for each prompt.
size
(string, optional, Default to ‘256x256’, possible values ‘256x256’ ‘512x512’ ‘1024x1024’)
The size of generated images
The complete source code
https://github.com/adelpro/benyahia-openAI
Conclusion
OpenAI npm package is a powerful package and under active development, in this article we have explain how to use it with NodeJS, with is recommended by their official documentation, with that your API keys will remain protected.
For more advanced topics or other use cases you are welcome to share your opinion and your experience